The examples are the most direct way to see TorchLean as a working system. Each page starts from something concrete: a model run, a graph, a tensor artifact, a saved log, a verifier result, or a bug pattern. The goal is to show how runnable ML code becomes an object that Lean can inspect, lower, check, or relate to a theorem.
Start with a small training run or the verification bounds page. For a systems-oriented view, read the text-model and diffusion walkthroughs. For the clearest motivation, read Bug Zoo.
Featured Examples
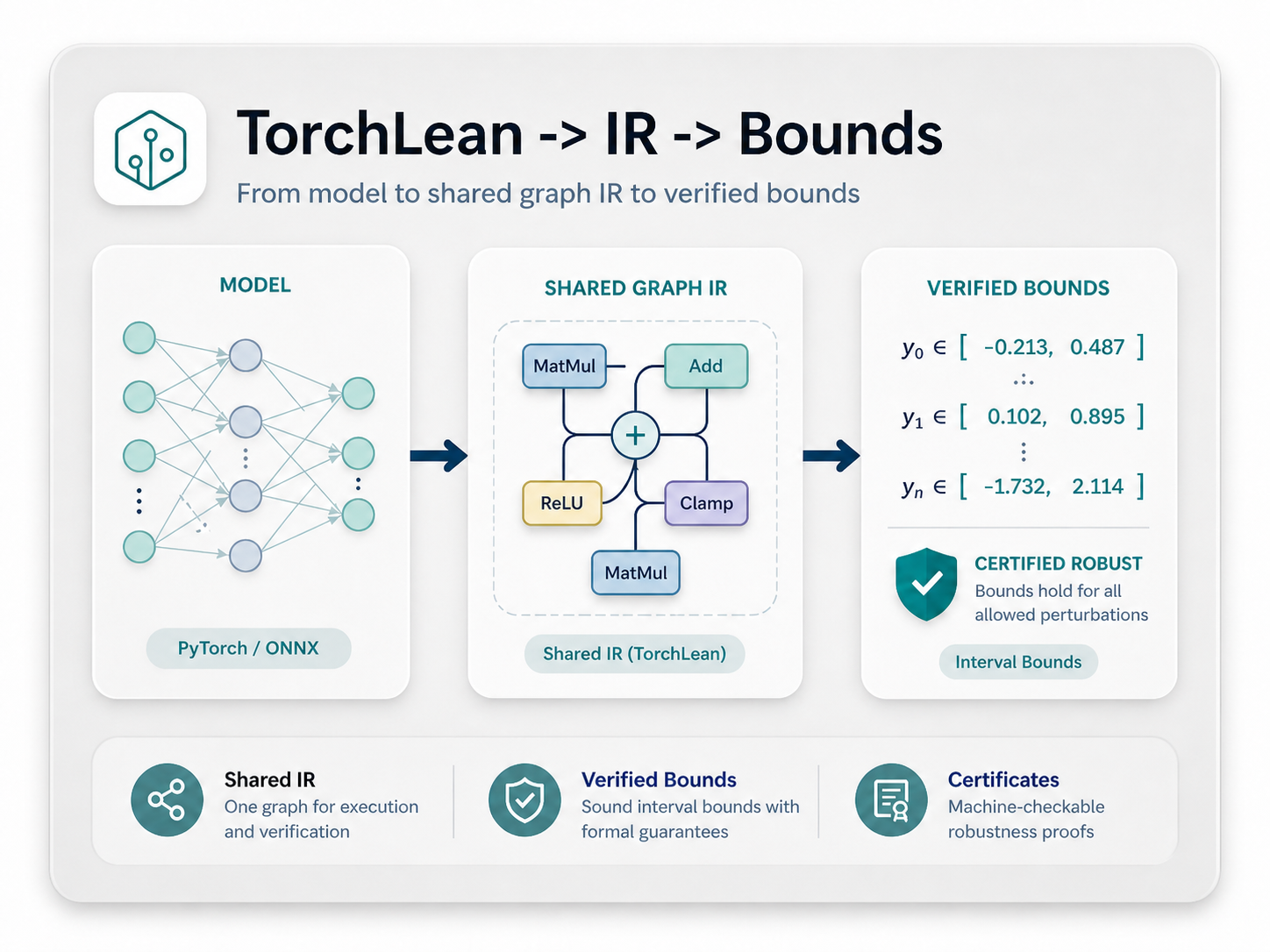 Graph IR and Bounds
Follow a small model as it becomes an op-tagged graph, then use that graph for shape checks, execution traces, and interval bounds.
Open guide page
Graph IR and Bounds
Follow a small model as it becomes an op-tagged graph, then use that graph for shape checks, execution traces, and interval bounds.
Open guide page
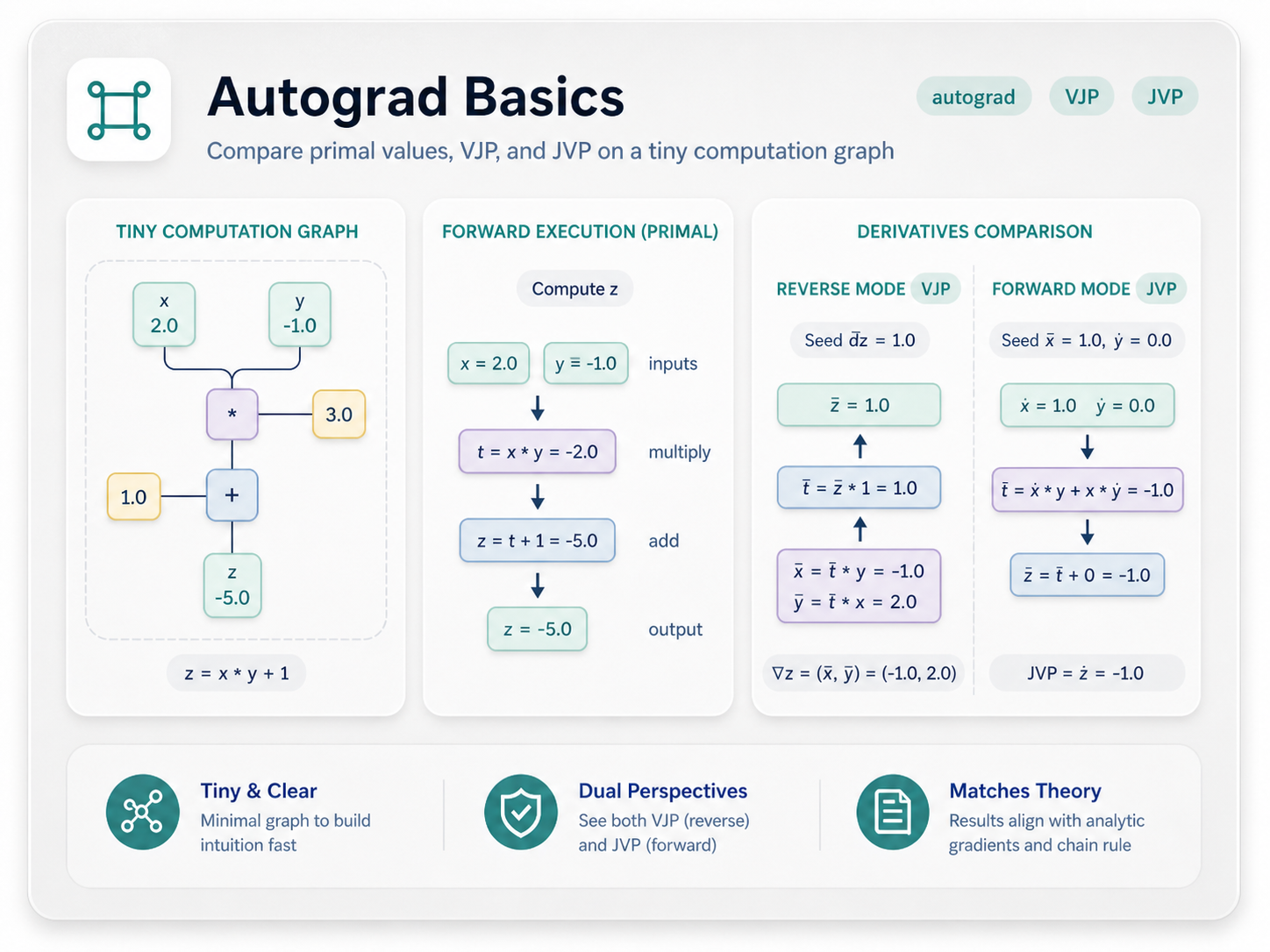 Autograd Basics
Compute gradients for small tensor functions, then inspect the tape and VJP objects that make reverse mode explicit.
Open guide page
Autograd Basics
Compute gradients for small tensor functions, then inspect the tape and VJP objects that make reverse mode explicit.
Open guide page
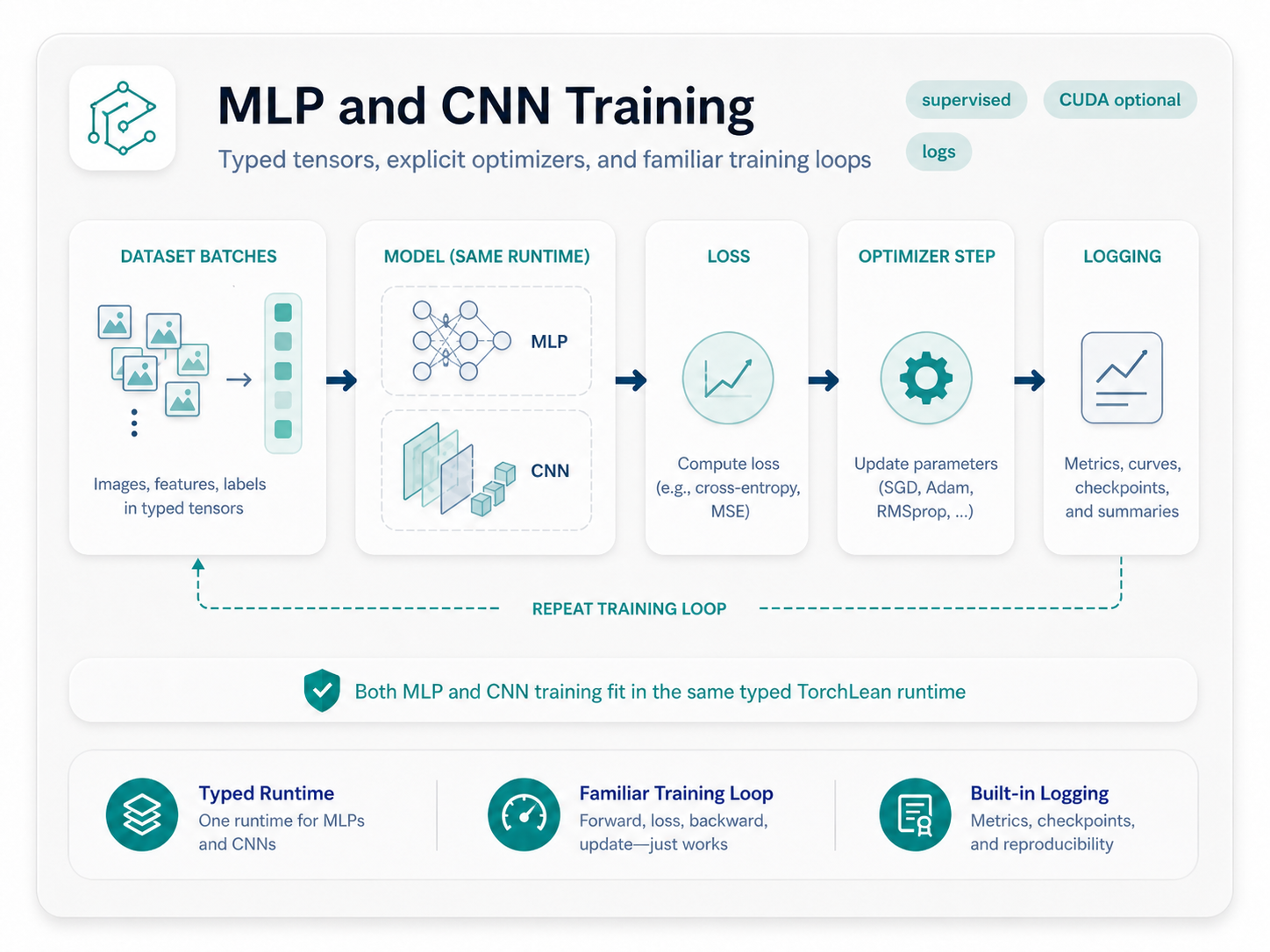 Supervised Training
Instantiate supervised models, build loaders, fit for multiple epochs or fixed steps, and save loss curves from the same Lean runner.
Open model examples docs
Supervised Training
Instantiate supervised models, build loaders, fit for multiple epochs or fixed steps, and save loss curves from the same Lean runner.
Open model examples docs
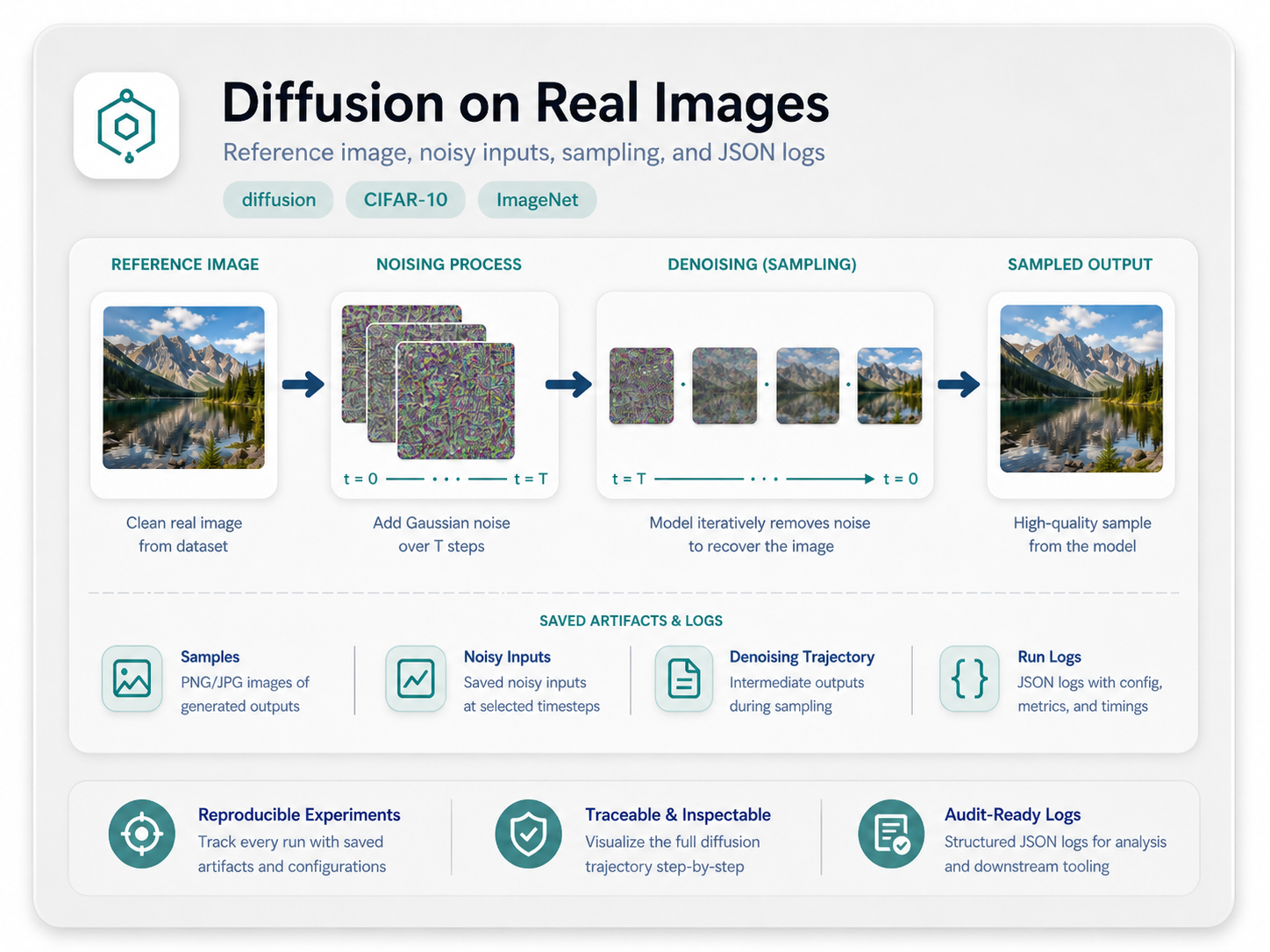 Diffusion
Train a small denoiser, run deterministic DDIM sampling, and inspect both the generated images and the saved loss log.
Open diffusion walkthrough
Diffusion
Train a small denoiser, run deterministic DDIM sampling, and inspect both the generated images and the saved loss log.
Open diffusion walkthrough
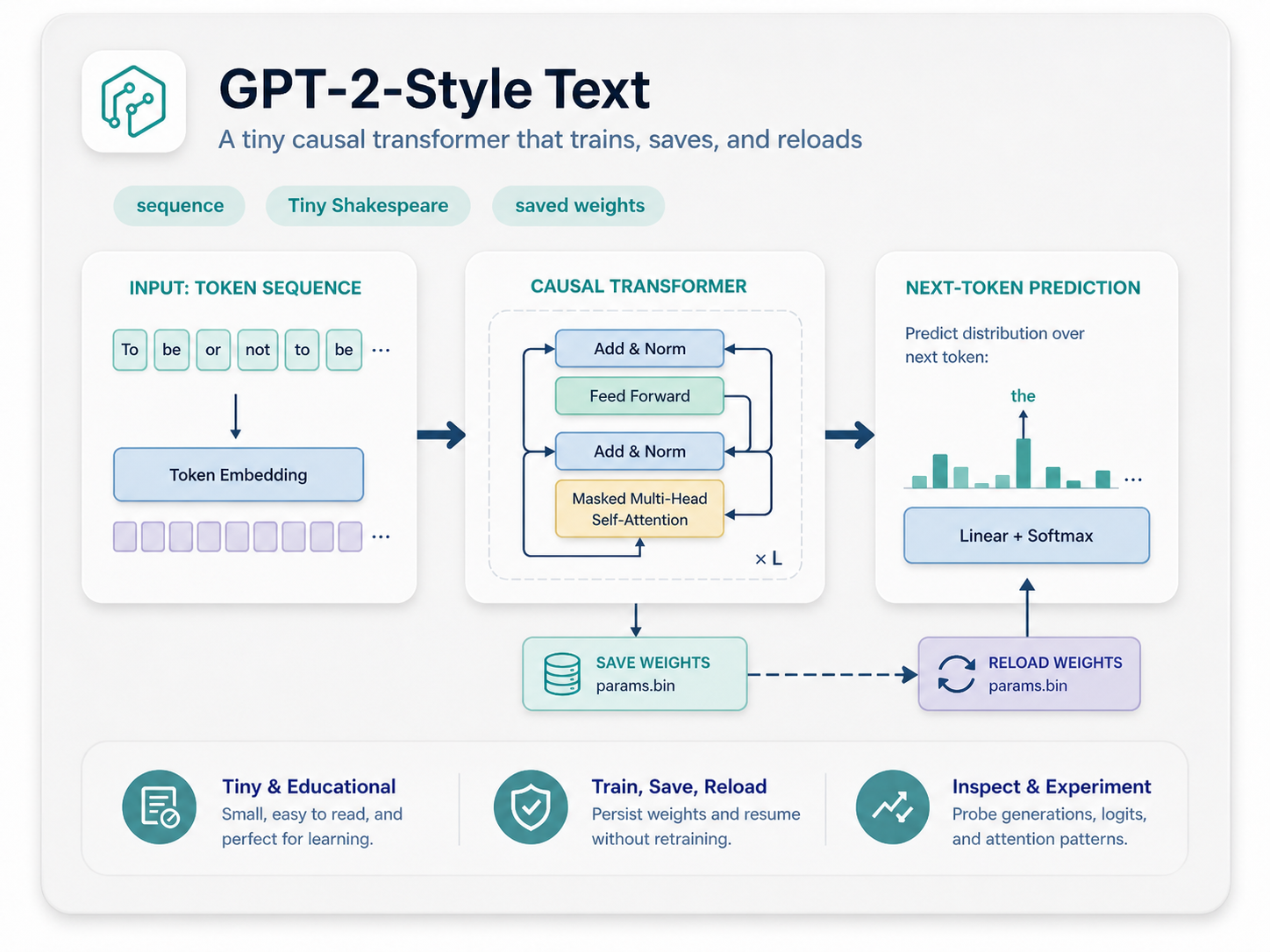 GPT-Style Text
Tokenize bytes, build next-token examples, train a small causal transformer, save parameters, and sample continuations.
Open text walkthrough
GPT-Style Text
Tokenize bytes, build next-token examples, train a small causal transformer, save parameters, and sample continuations.
Open text walkthrough
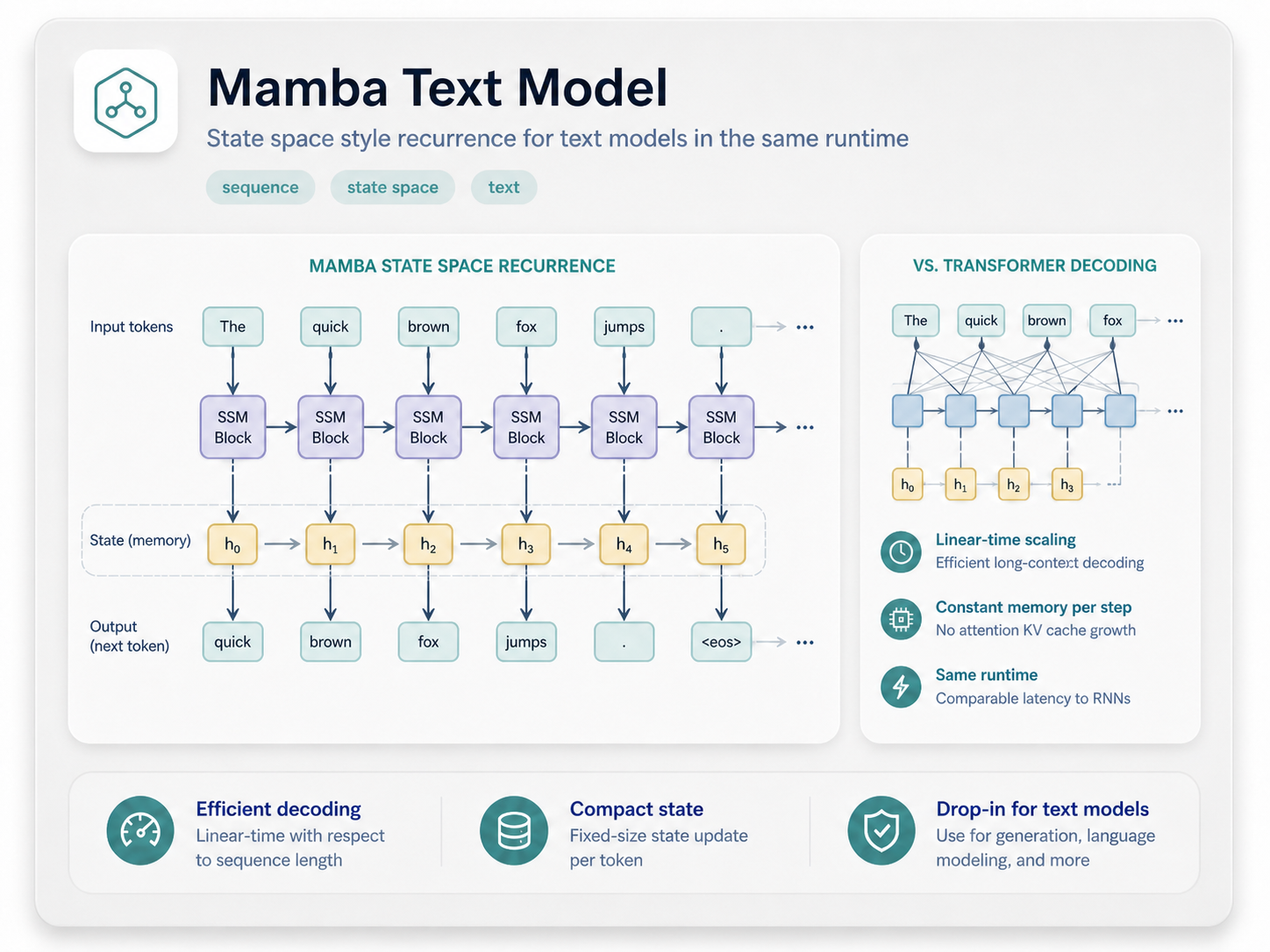 Mamba Text Model
Use the same corpus and logging path with a compact state-space sequence model instead of attention.
Open text walkthrough
Mamba Text Model
Use the same corpus and logging path with a compact state-space sequence model instead of attention.
Open text walkthrough
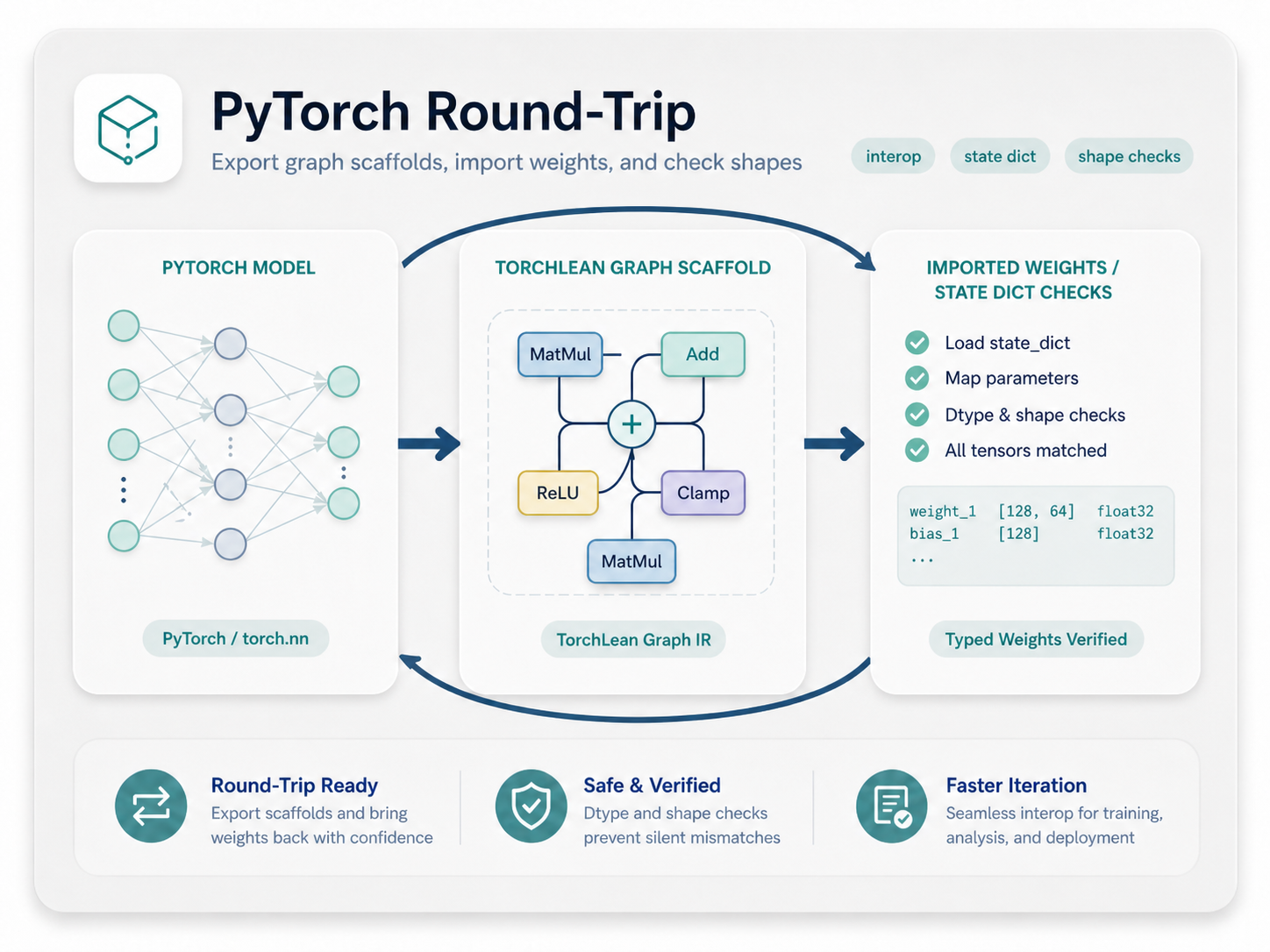 PyTorch Round Trip
Move weights across the Python boundary while keeping tensor shapes, parameter packs, and import checks visible.
Open interop guide
PyTorch Round Trip
Move weights across the Python boundary while keeping tensor shapes, parameter packs, and import checks visible.
Open interop guide
 Float32 and IEEE-754
Compare real specifications, rounded `FP32` models, executable IEEE bit semantics, and runtime `Float32` bridge assumptions.
Open floating-point guide
Float32 and IEEE-754
Compare real specifications, rounded `FP32` models, executable IEEE bit semantics, and runtime `Float32` bridge assumptions.
Open floating-point guide
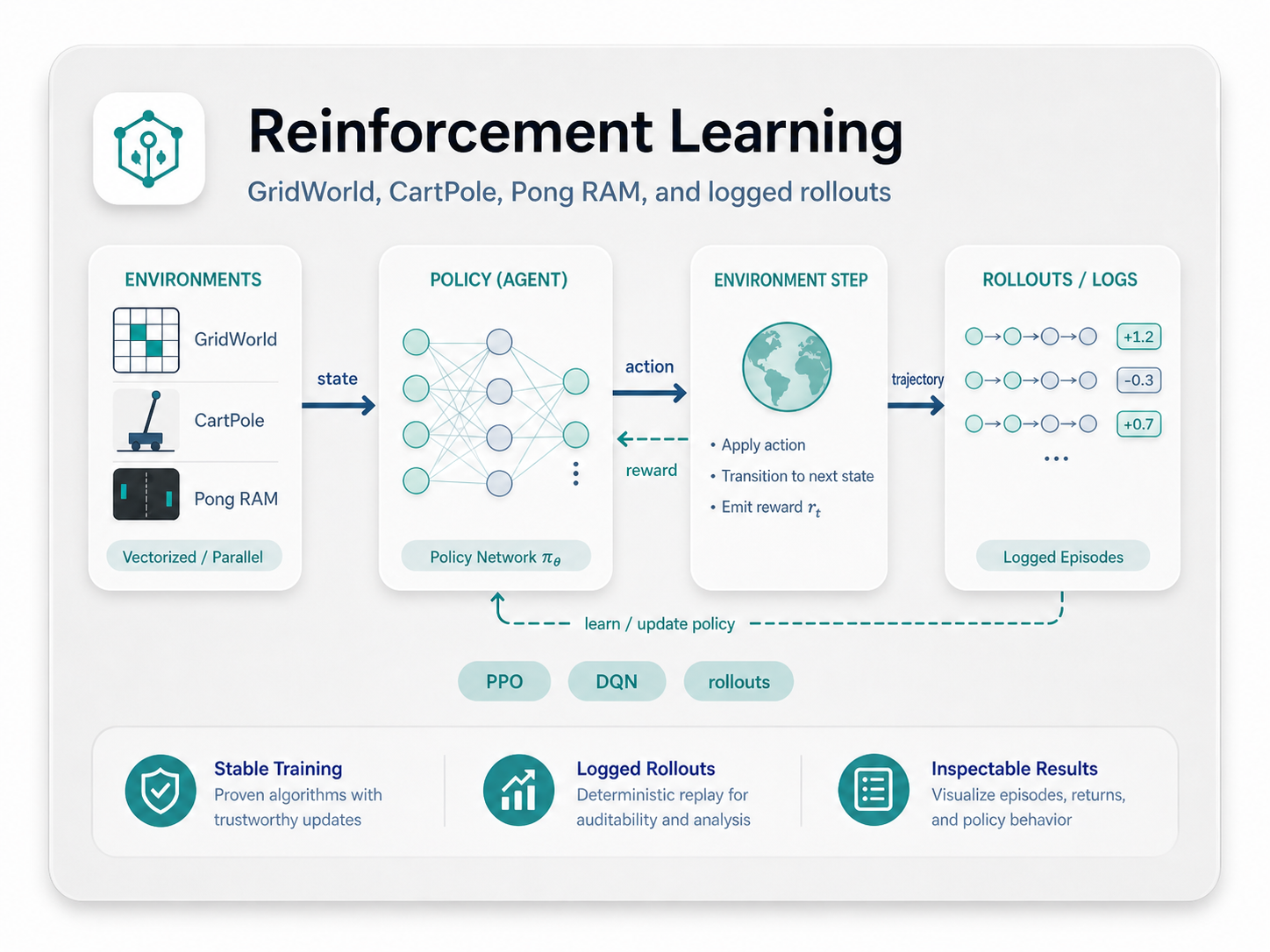 Reinforcement Learning
Run PPO on Lean-native and Gymnasium environments, then inspect the rollout, reward, and policy artifacts that enter training.
Open RL example docs
Reinforcement Learning
Run PPO on Lean-native and Gymnasium environments, then inspect the rollout, reward, and policy artifacts that enter training.
Open RL example docs
 Bug Zoo
See how common ML bugs become small Lean contracts: causal masks, KV caches, token ids, normalization state, batching, and Float32 behavior.
Open Bug Zoo walkthrough
Bug Zoo
See how common ML bugs become small Lean contracts: causal masks, KV caches, token ids, normalization state, batching, and Float32 behavior.
Open Bug Zoo walkthrough
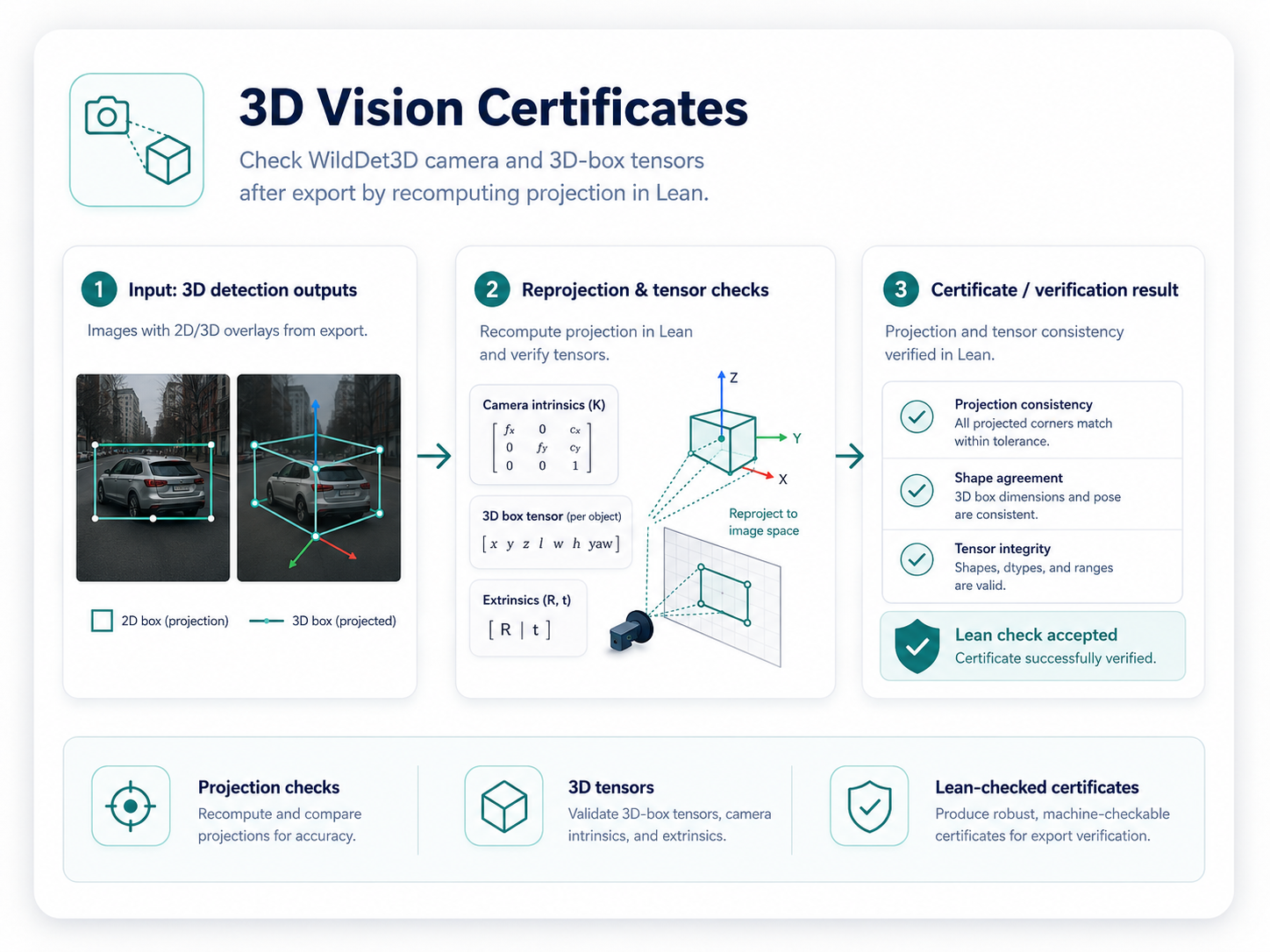 3D Vision Certificates
Export camera and box tensors from a detector, recompute projection in Lean, and reject boxes that do not enclose projected corners.
Open 3D vision tutorial
3D Vision Certificates
Export camera and box tensors from a detector, recompute projection in Lean, and reject boxes that do not enclose projected corners.
Open 3D vision tutorial
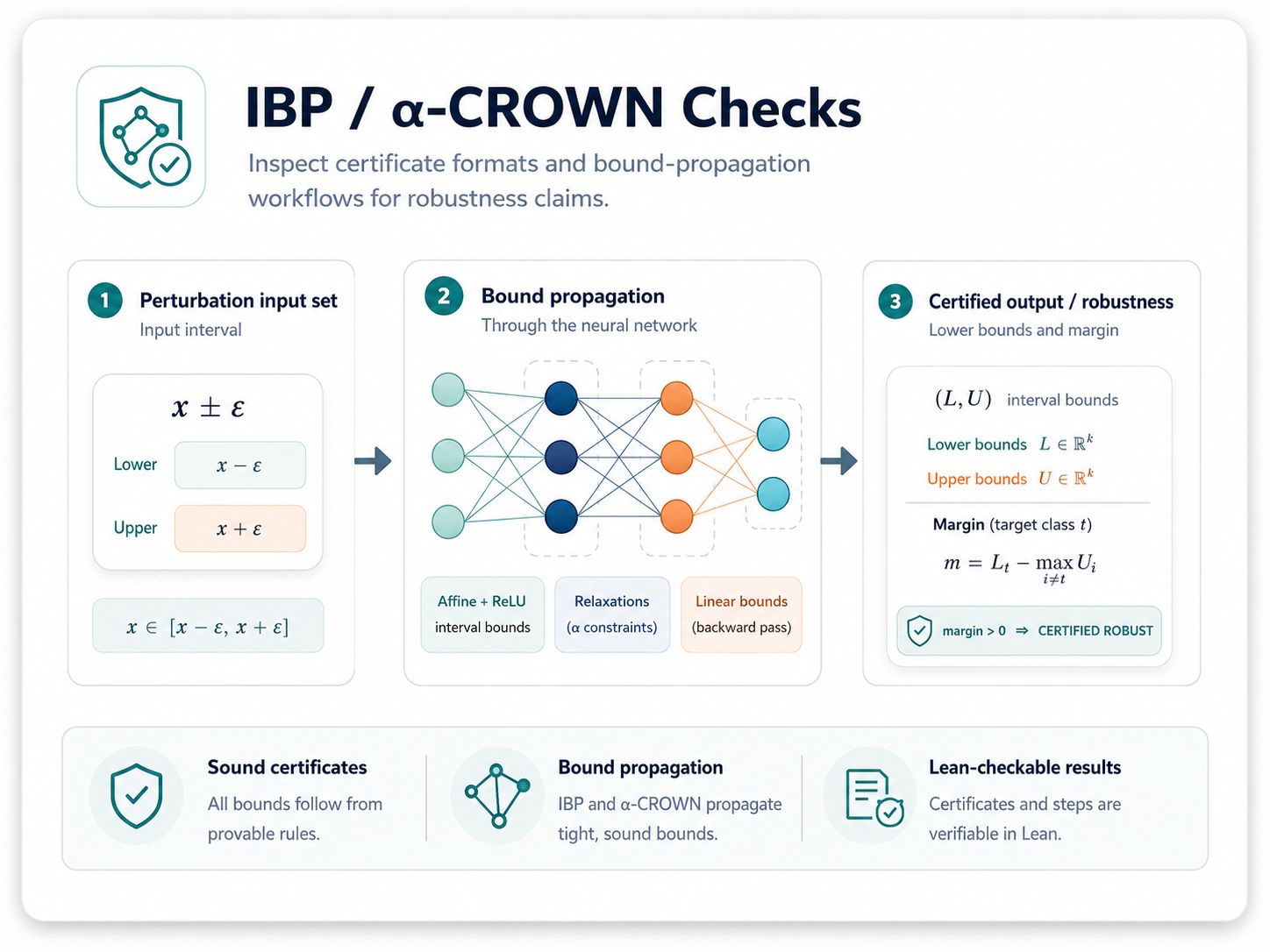 IBP and CROWN Verification
Attach input boxes to an IR graph, propagate interval or affine bounds, and check small external certificates through Lean.
Open verification tutorial
IBP and CROWN Verification
Attach input boxes to an IR graph, propagate interval or affine bounds, and check small external certificates through Lean.
Open verification tutorial
CUDA is opt-in. The build flags, runtime path, and agreement assumptions are explained in
GPU and CUDA.
For long CUDA training runs, model commands also expose allocator telemetry through
--cuda-mem-watch N; longer runs choose a small default cadence so device-memory behavior is visible
while the example is running.
The guide also covers the newer runtime-facing APIs used by larger examples: runtime-side Float initializers, typed step streams for generated or file-backed batches, and integer-token GPT helpers that avoid one-hot targets for language-model training.